No sos vos: son los datos (parte I)

Por Walter Alini para La tinta
The Economist, en el año 2017 (y varies otres antes), nos tiró la posta, atenti: «El recurso más valioso del mundo no es más el petróleo, sino los datos».
No sé si alguna vez fue el petróleo, seguramente sí, pero no soy especialista en petróleo. Tampoco en datos, pero me la rebusco bastante mejor. Así que veamos, en una serie de textos, de intentar bajar algunos conceptos a tierra y de bajar también la espuma en algunas cosas (y subirla en otras). Llevar tranquilidad (y generar preocupación). En definitiva, generar conciencia, que creo que de eso se trata.
No saldremos siendo especialistas en nada, pero sí creo que podremos agregar algunas sensaciones y visiones distintas a las que traíamos. Será una victoria si esto sucede.
Los básicos
Empecemos con algunas pocas nociones y definiciones. No pretendo que sean estrictas, pero sí que sirvan como puntos de referencia, porque después no quiero llantos (?):
Ciencia de Datos (Data Science, DS): Es crear productos a partir de datos. Un producto de datos tiene más facha de petróleo que un dato, esencialmente porque es la forma de refinar ese petróleo. Si bien el acceso a los datos siempre es una ventaja, tenerlos sin más solo insume dinero o es una ventaja en estado potencial. El valor está en qué hacemos con los datos. Una cosa es agrupar un montón de números y de nombres, y otra cosa es tener una guía telefónica. Ejemplo bien 1.0.
Aprendizaje automático (Machine Learning, ML): Es un programa de computación (software) que generaliza a partir de datos existentes. Supongamos que tenemos un listado de todos los vuelos de Córdoba a Buenos Aires, para todas las líneas aéreas que operaron históricamente la ruta, con datos climáticos, modelos de avión, estado de la pista, horario de salida, horario de llegada, etc. Podríamos escribir un programa de software que, a partir de esos datos del pasado, prediga cuándo llegará a destino el vuelo de Córdoba a Buenos Aires que partirá mañana a primera hora por Aerolíneas Argentinas. La verdad es que no sabemos con exactitud a qué hora llegará, pero, en función de los datos históricos de eventos similares, nos podemos dar maña para tener una predicción. Esta predicción puede ser buena o mala, y su precisión solo la conoceremos cuando el avión en cuestión aterrice en Buenos Aires.
Ah, qué pícare, saco el promedio de la duración de vuelos del último año y listo. Bueno, sí, eso es efectivamente un posible modelo de Machine Learning. La ciencia es un poco más compleja que eso y tiene muchas formas y variantes, pero el acercamiento es correcto.
Adicionalmente a estos dos conceptos, que son los que me interesa traer por ahora, tenemos muchos más dando vueltas: Inteligencia Artificial (Artificial Intelligence, AI), Aprendizaje Profundo (Deep Learning, DL), Visión por Computadoras (Computer Vision, CV), Macrodatos o Datos Masivos (Big Data, BD) y algunos más. Digamos que si por todos entendemos lo mismo, no nos vamos a pelear demasiado hasta el final de esta serie de textos. Para ellos, y a partir de ahora, me tomaré licencias muy generosas para intercambiar a piacere entre casi cualquiera de estos conceptos.
Los básicos II: el proceso
Me gustaría contar con un poco (y solo un poco) más de detalle cómo es el proceso de generalización de datos.
Hay una principal diferencia conceptual entre la forma de hacer un programa, digamos, tradicional, y la forma de hacer un programa de aprendizaje automático.
Simplificando, un programa tradicional consta de uno o más archivos de código (lenguaje que la computadora sabe entender para ejecutar determinados pasos) y una o más formas de “ingresar” información (datos), bien a través de interacciones con ese programa o bien a través de información digital (que también es una forma de interactuar con ese programa) para obtener un resultado:
Programa + Datos = Resultado
La lógica para la generalización de datos tiene un rulo más. A partir de un montón de resultados y de datos, generamos un programa:
Resultados + Datos = Programa (modelo)
¿Y para qué me sirve ese programa? Bueno, para usarlo de la forma tradicional, y a partir de un dato “nuevo”, obtener un resultado “nuevo”:
Programa (modelo) + Datos = ResultadoML
Con el ejemplo de los vuelos de la sección anterior, supongamos que tenemos los siguientes datos:
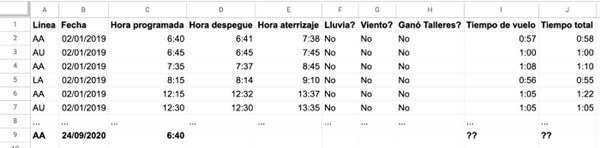
Si queremos predecir tiempo total, por ejemplo, vamos a utilizar los datos de las primeras filas para entrenar un modelo. Esto es para que, a partir de los datos con los que contamos y los resultados (tiempo total), generemos un programa que sea capaz de, ante un nuevo vuelo (que aún no despegó), obtener una predicción del resultado que buscamos.
Algo más: una vez que ese nuevo vuelo aterrizó, y contamos con los datos que a priori eran predicciones y que ahora son concretos, estamos habilitados a dos cosas: por un lado, a determinar la precisión de nuestro modelo (qué tan bien o mal predijo este vuelo en particular). Por otro lado, a reentrenar el modelo con más datos (el de este vuelo). En la gran mayoría de las veces, más datos es mejor: tenemos más información disponible.
Metí de pecho dos conceptos, que son los de entrenamiento y reentrenamiento, que espero resuenen mejor que antes.
Un detalle. En general, no usamos todos los datos disponibles para entrenar un modelo de Machine Learning, sino que solemos agarrar una gran parte para entrenar y reservar otra parte de los datos completos que tenemos para “evaluar” al modelo. Nos guardamos algunos datos sobre los cuales sabemos tiempos total y probamos al modelo para intentar determinar su capacidad de hacer buenas predicciones.
Otro detalle. La adquisición de datos puede hacerse de manera automática y/o de manera manual. Por ejemplo, para determinar si en una foto hay un gatito, será necesaria al menos una parte de adquisición manual de datos: sentar frente a una computadora a personas para que indiquen si aparecen gatitos en un conjunto de imágenes (y posiblemente para que indiquen en qué parte de la imagen).
Es curioso e interesante lo que hizo la empresa reCaptcha (empresa adquirida por Google en el año 2009). reCaptcha brinda el servicio de captchas para la web. Un captcha es una forma de determinar con bastante certeza si estamos frente a un ser humano o ante un programa que está actuando a través de una interfaz (algo que queremos evitar en ciertos casos) presentando un desafío que, en teoría, solo los humanos lo pueden resolver. Como, por ejemplo, ingresar en texto dos palabras que se ven en una imagen:
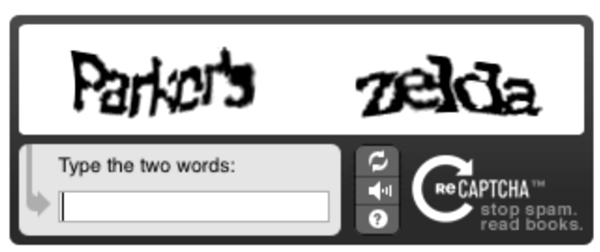
Las dos palabras que mostraba reCaptcha cumplían la característica de ser una conocida por el sistema y la otra no, división desconocida para le usuarie. Por lo tanto, funcionaba como lucha contra el SPAM (a través de identificar humanos detrás de las computadoras) y como un método para digitalizar libros (que, a posteriori, utilizó Google para Google Books). Hermosa forma de adquirir datos validados por terceros de forma masiva y gratuita.
Bueno, ¿y?
Nada de esto es magia. Contadores, astrónomes, estadistas, matemátiques y muches otres vienen haciendo Machine Learning desde hace mucho, sin saber de este término. Machine Learning, como regla del pulgar, tiene tope de eficiencia similar a lo que un especialista podría lograr con métodos de vieja escuela. Con infinito tiempo e infinitos datos, vamos a decir, pero esta es la parte de “no hay magia”.
Lo que cambió en el último tiempo es la capacidad de cómputo y de almacenamiento de información. Y también la velocidad de ambas cosas. Tenemos más y mejores técnicas de cómputo, y tenemos accesos cada vez más baratos a almacenamiento de datos. En este punto, Amazon es punta de lanza: no solo está involucrado en el manejo masivo de datos para su negocio, sino que, además, cuenta con uno de los mejores servicios de almacenamiento y capacidad de cómputo de la industria: Amazon Web Services es pilar para la gran mayoría de las empresas que hacen uso intensivo de datos. Primera alarma para ellas (sobre todo, para las que le compiten a Amazon, como Mercado Libre, E-Bay, Alibaba, etc.): es posible que sus decisiones de dónde alojar sus datos (y de cómo tratarlos y manipularlos) venga acompañada de un análisis e interés estratégico de quiénes están por detrás de ellos, tanto por el valor económico del servicio como por el potencial peligro de tener los datos en la casa del competidor.
Acá se abren dos puntos que me parecen interesantes tratar: uno está relacionado con el uso de los datos y el otro con las cuestiones de privacidad alrededor de los datos. Esto es: ¿qué tiene que ver todo esto conmigo y por qué (si es que) debería preocuparme?
Les invito a encontrarnos en el próximo artículo para intentar darle seguimiento a estas preguntas.
*Por Walter Alini para La tinta / Ilustración de portada: JPBellini.



